Hi @natureshadow, schön dass du hier bist!
Deinen Vorschlag von Matrix für Föderation hatte auch @preya schon in den Raum geworfen. Ich bin generell daran interessiert (wir überlegen ja auch, für Chat-Kommunikation von Slack dorthin umzuziehen), aber bleibe skeptisch ob es die richtige Technologie ist. Ich mache mir insbesondere Sorgen aufgrund der Datenmenge. In meiner Vorstellung geht es ja nicht um live-Daten, und die Datenpipeline ist auch unidirektional.
Meine Idee einer naiven Implementation wäre eher vergleichbar mit dem Keyserver-System von GPG (natürlich ohne dessen Probleme der Unlöschbarkeit etc.), bei dem die Plattformen, wie auch immer, ihren verarbeiteten Datensatz veröffentlichen, und ein zentraler „Pool“ sich diese Daten jeweils herunterlädt und zusammenführt in einen Gesamtdatensatz. Ich glaube, die Daten sollten nicht als JSON vorliegen, hier haben wir jetzt schon Platz- und Performanceprobleme. Aber vielleicht hilft ja Matrix bei der Koordinierung und Verwaltung dieses Schemas, während die tatsächlichen Daten anders formatiert und über einen anderen Kanal übermittelt werden.
Vielleicht haben du und @preya ja Lust mal zu dritt (oder vielleicht wollen noch mehr?) darüber zu diskutieren. Ihr scheint euch da gut auszukennen, da würde ich mich sehr freuen das vorgestellt zu bekommen.
LG

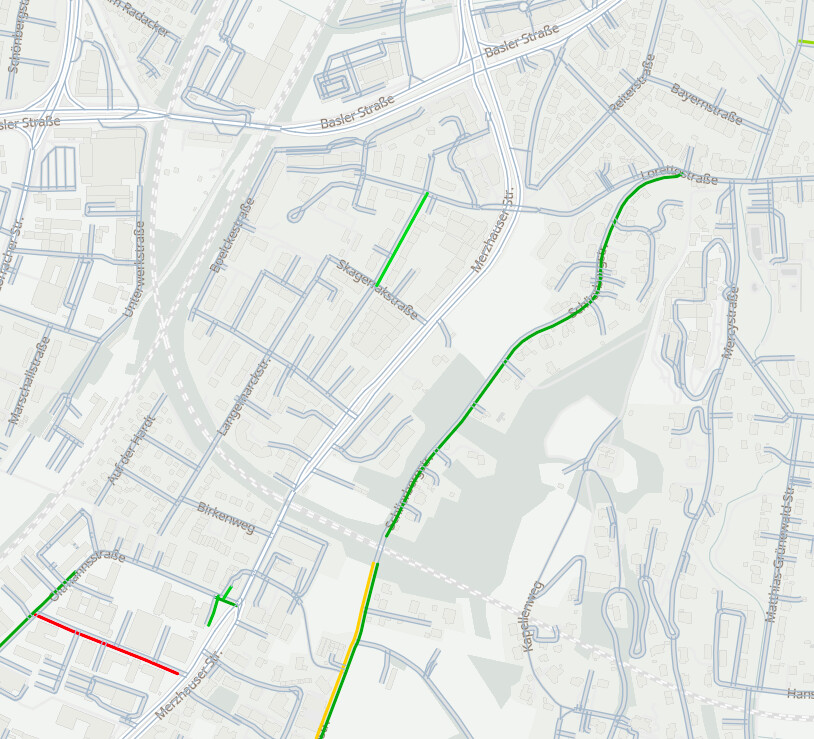
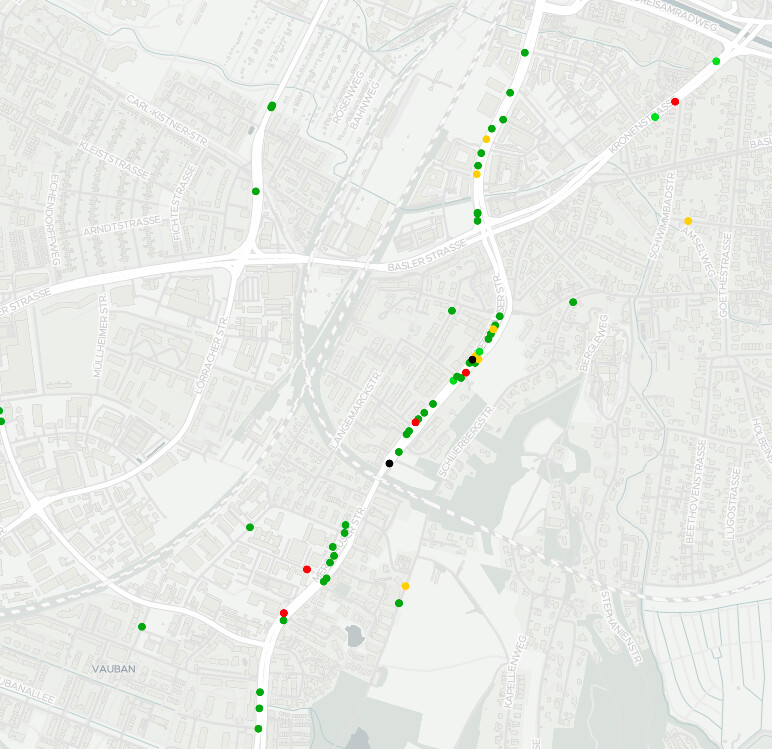

 Aber das finden wir auch noch raus.
Aber das finden wir auch noch raus.
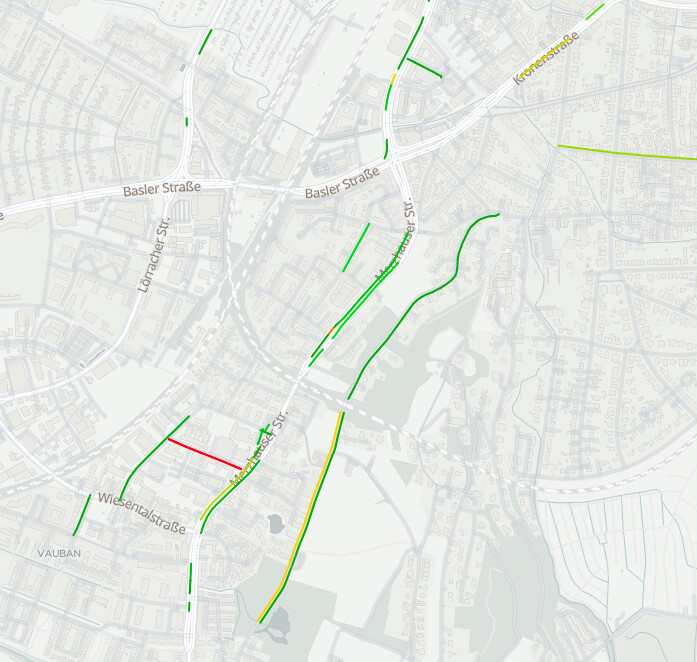

 ).
).