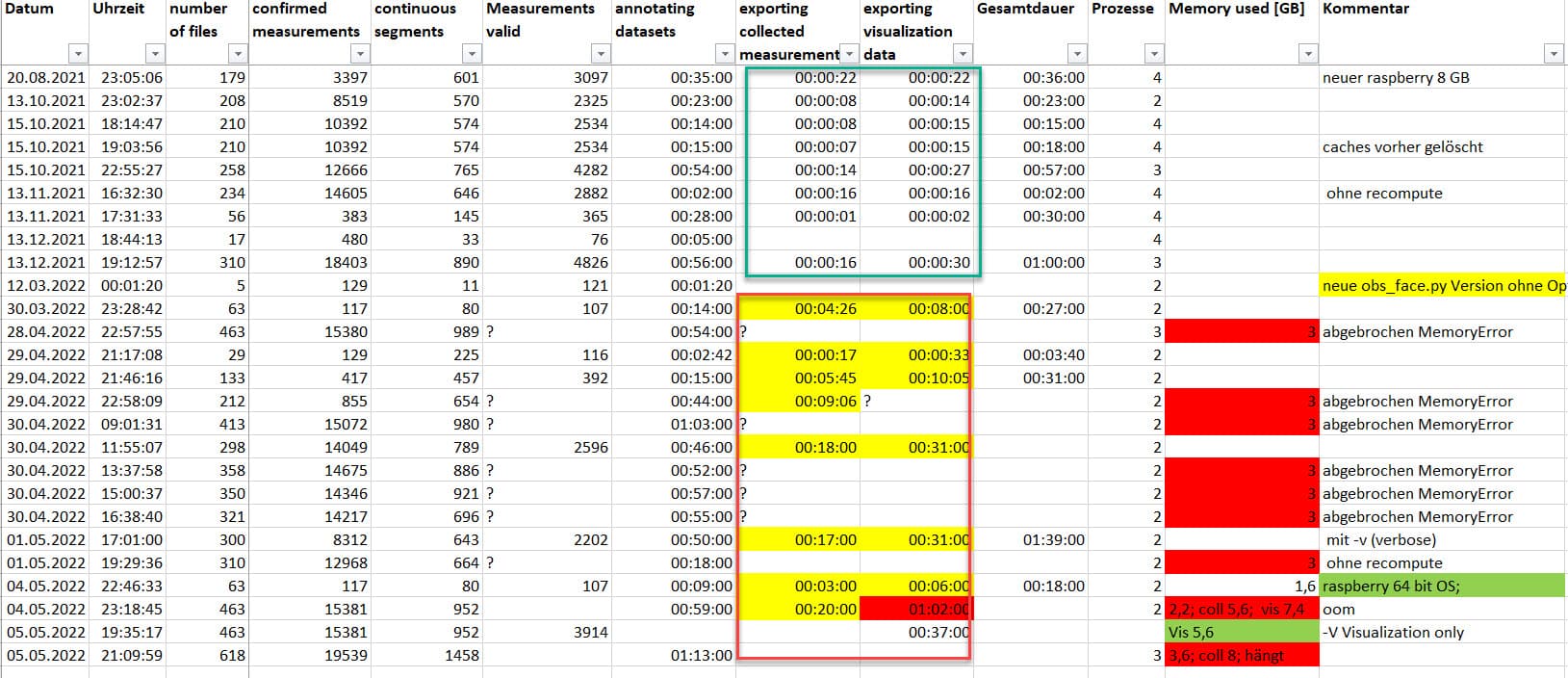
Ich habe im März die neue Version des GitHub - openbikesensor/OpenBikeSensor-Scripts installiert.
Seit dieser Zeit laufen die Schritte
- exporting collected measurements und
- exporting visualization data
um ein vielfaches länger und benötigen sehr viel Memory. Die annotation läuft wie vorher ohne Probleme.
Beispiel:
vorher bei ca. 200 csv files: - 8 s: exporting collected measurements und
- 16 s: exporting visualization data
seit März - 9 Min: exporting collected measurements
- 18 Min: exporting visualization data
zudem steigt der Memory-Verbrauch bei den beiden Schritten plötzlich stark an.
Mein raspberry pi 4 Model B mit 8 GB ist dann bei 3 GB abgebrochen (war noch 32 bit OS).
Jetzt habe ich das 64 bit OS und bereits
463 files / 3914 measurments valid durchgebracht.
Bei 618 files ist der raspberry kaum noch ansprechbar, da er dann die 8 GB Grenze erreicht hat und swapt.
Ist das ein bug?
Anbei die Statistik der Läufe von obs_face.py
Der letzte Lauf ist jetzt im Schritt mit 6251 measurements valid Visualisierung durchgelaufen: mit 6:14 hh:mm und 10,2 GB Memory (bei 8 GB Phys Mem und 8 GB Swap).