
Moin zusammen,
Ich möchte demnächst mit den ersten gesammelten Daten meiner Heimatkommune hausieren gehen. Gibt es denn irgendwo (Python-)Skripte, mit denen die Daten automatisch ausgewertet und in straßenspezifische Berichte gegossen werden? Wenn ja, wie finde ich die?
Grüße, und … wählt ordentlich 
@Fietsekapitän Nein, sowas haben wir bisher nicht in dem Automatisierungsgrad, dass da Berichte für Straßen rausfallen. Derzeit können die Portale json für openstreetmap segmente und für Überholevents ausspucken. Darauf bsierend gibt es zwei repositories, in denen sich menschen Gedanken zu Auswertungen gemacht haben, bisher vor allem zu den Events. einmal dieses von @simse von der TH Wildau und dieses von @boldt
1 „Gefällt mir“
hier noch ein drittes mit der möglichkeit selbst gewählte kriterien zu untersuchen. Aber auch nicht komplett automatisch
3 „Gefällt mir“
Herzlichen Dank! Läuft 
Moin, mir erschien dieses Analysepaket am passendsten für meine Zwecke. Ich habe dann am Ende vom Skript 1_2 kurzerhand folgenden Block eingefügt:
df = gdf_kombi
# Liste der eindeutigen Einträge in der Spalte "name", die häufiger als 20 Mal vorkommen
frequent_names = df['name'].value_counts()[df['name'].value_counts() > 20].index.tolist()
# Bins definieren
bins = np.arange(0, 3.25, 0.25)
bins = np.append(bins, np.inf) # Alles über 3 zusammenfassen
# Schleife durch die häufigen Namen und Erstellen der Histogramme
for name in frequent_names:
subset = df[df['name'] == name]
plt.figure(figsize=(10, 6))
# Histogramm plotten
n, bins, patches = plt.hist(subset['distance_overtaker'], bins=bins, alpha=0.7, edgecolor='black')
# Farben anpassen
for patch, left_edge in zip(patches, bins[:-1]):
if left_edge < 1.5:
patch.set_facecolor('red')
elif left_edge < 2:
patch.set_facecolor('orange')
else:
patch.set_facecolor('green')
plt.title(f'ADFC/OpenBikeSensor-Messungen für {name}, {len(subset)} Überholungen')
plt.xlabel('Überholabstand [m]')
plt.ylabel('Häufigkeit')
plt.grid(axis='y', alpha=0.75)
filename = "../Ergebnisse/" + name.replace(' ', '_') + '.png'
plt.savefig(filename, facecolor='white', transparent=False)
plt.show()
Damit kommen dann so schöne, populistische Bildchen heraus wie das hier:
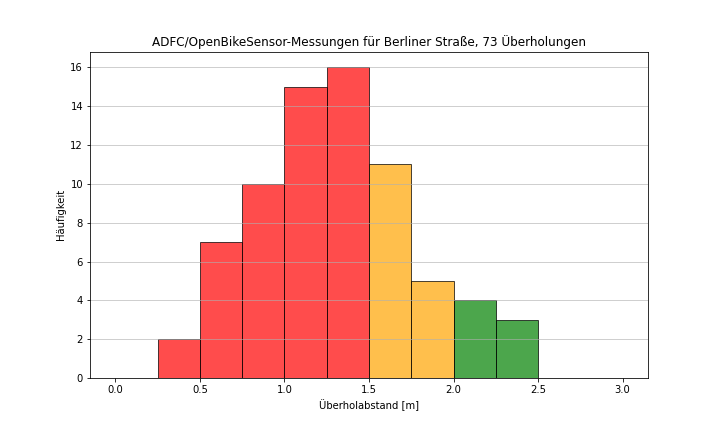
1 „Gefällt mir“
Moin!
Das freut mich, dass das Script weiter genutzt wird! Dann hat sich die ganze Arbeit ja doch gelohnt
Die Zusammenfassung nach Namen und das Ausgeben in der Schleife ist vom Arbeitsaufwand auch clever - auch wenn ich aus meinem Blickwinkel gleich anmerken will, dass schon in der Berliner Straße dabei ganz unterschiedliche Arten von Infrastruktur zusammengefasst werden Je nachdem was erreicht werden soll kann das ja aber trotzdem gut sein! Du musst nur aufpassen, dass du keine anderen „Berliner Straßen“ mit drin hast sondern nur die aus deiner Kommune…
Und ob ihr legale Abstände noch in gelb darstellen möchtet müsst ihr auch selbst wissen. Ich denke, dass das einen aber auch angreifbar machen kann, eben mit dem Vorwurf zu populistisch zu sein. Vielleicht eher ein helles grün? Oder in Anlehnung ans OBS-Portal, das finde ich auch echt gelungen.
Ansonsten wünsch ich euch viel Erfolg mit eurer Kampagne!
1 „Gefällt mir“
Danke
Du hast vollkommen recht was die Zusammenfassung der Infrastruktur angeht! In diesem Fall ist das Absicht, weil ich zunächst mal überhaupt aufzeigen möchte, dass es ein Problem gibt. Natürlich muss dazu noch irgendwo Kleingedrucktes hingeworfen werden 
Die Einteilung in Abschnitte würde ich vornehmen, wenn wir dann ins Gespräch gekommen sind und uns Details anschauen.
Legale Abstände in gelb - ich wollte argumentieren, dass man für Kinder ja 2m braucht und dass der Bereich zwischen 1,5m und 2m deswegen durchaus gelb sein kann. Aber: Ich finde die Kinderregel nicht in der StVO!?
Genau, das habe ich verwendet.
Ah, so macht es dann Sinn. In der StVO steht das auch nicht, da nur die 1,5m inner und 2m außerorts. Es gab wohl aber mal ein Urteil des OLG Naumenburg (AZ 12 U 29/05), aus dem der Wert von 2m mit Kind auf dem Rad kommt.
1 „Gefällt mir“
In Python bin ich leider nicht firm.
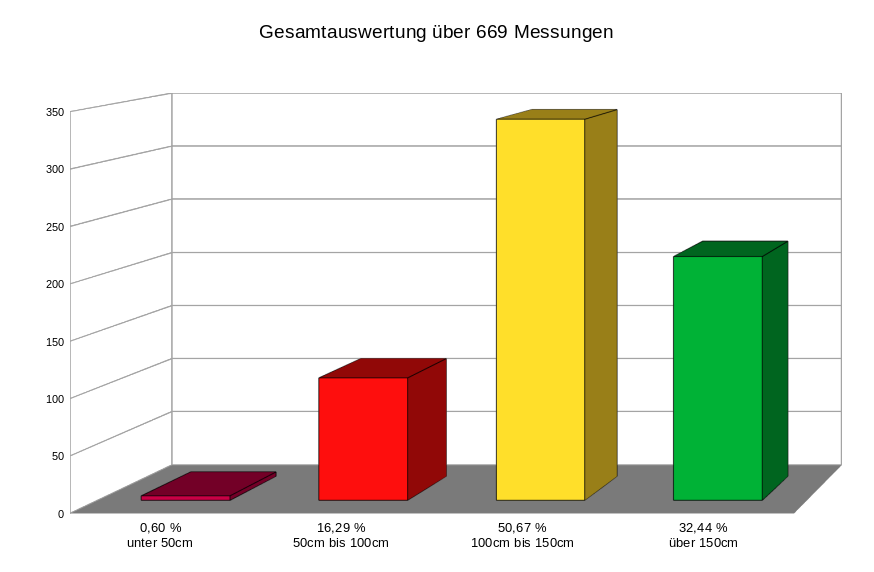
Für die Auswertung unserer letzten Messfahrten hab ich mich deswegen mit LibreOffice Calc etwas beschäftigt.
Die CSV Dateien importieren ist ja kein großes Hindernis, Import ab Zeile 2 und ; als Feldtrenner.
Mit der Formel
=ZÄHLENWENNS(O$2:O$4000;">0";M$2:M$4000;">50";M$2:M$4000;"<101")
hab ich schon mal die Anzahl der Messungen im Bereich zwischen 50cm und 100cm Abstand
Da die Verteilung in Prozentwerten auswerfen und ein Diagramm basteln ist auch nicht sonderlich anspruchsvoll.
Rauspurzelt dann sowas
In Python einarbeiten und das Problem damit zukünftig lösen möchte ich aber trotzdem.
Allenfalls kann ich dir helfen. Ich habe mir von ChatGPT Python-Code erstellen lassen, mit welchem ich die Daten auswerten kann.
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def main():
# Pfad zur GeoJSON-Datei (bitte ggf. anpassen)
geojson_file = "ueberholungen_alle_auswertung.json"
# GeoJSON-Daten einlesen
try:
gdf = gpd.read_file(geojson_file)
except Exception as e:
print(f"Fehler beim Einlesen der GeoJSON-Datei: {e}")
return
# Überprüfen, ob das Feld "distance_overtaker" vorhanden ist
if "distance_overtaker" not in gdf.columns:
print("Das Feld 'distance_overtaker' wurde nicht gefunden.")
return
# Alle Werte extrahieren und fehlende Werte entfernen
original_distances = gdf["distance_overtaker"].dropna()
original_count = original_distances.count()
# Bestimme, wie viele Werte unter 0.15 und über 2.85 liegen
excluded_lower = original_distances[original_distances < 0.15].count()
excluded_upper = original_distances[original_distances > 2.85].count()
# Ausschließen von Werten < 0.15 und > 2.85
distances = original_distances[(original_distances >= 0.15) & (original_distances <= 2.85)]
total_n = distances.count()
# Deskriptive Statistiken berechnen
desc_stats = distances.describe() # count, mean, std, min, 25%, 50%, 75%, max
median = distances.median()
variance = distances.var()
iqr = desc_stats["75%"] - desc_stats["25%"]
mode_values = distances.mode()
mode_str = ", ".join(map(str, mode_values.tolist()))
# Ergebnisse in ein DataFrame verpacken (numerische Werte werden gerundet)
stats_df = pd.DataFrame({
"Wert": [
desc_stats["count"],
desc_stats["mean"],
desc_stats["std"],
desc_stats["min"],
desc_stats["25%"],
median,
desc_stats["75%"],
desc_stats["max"],
variance,
iqr,
mode_str
]
}, index=["Count", "Mean", "Std", "Min", "25%", "Median", "75%", "Max", "Variance", "IQR", "Mode"])
stats_df.loc[["Mean", "Std", "Min", "25%", "Median", "75%", "Max", "Variance", "IQR"]] = \
stats_df.loc[["Mean", "Std", "Min", "25%", "Median", "75%", "Max", "Variance", "IQR"]].astype(float).round(2)
# Hinweistext (wird in der Ausgabe und in den Diagrammen angezeigt)
exclusion_info = (f"Hinweis: Es wurden {excluded_lower} Messungen mit 'distance_overtaker' < 0.15 "
f"und {excluded_upper} Messungen mit 'distance_overtaker' > 2.85 ausgeschlossen.")
print("Deskriptive Statistiken zu 'distance_overtaker' (Werte zwischen 0.15 und 2.85):")
print(stats_df)
print(f"\nUrsprüngliche Gesamtanzahl (N): {original_count}")
print(f"Nach Ausschluss (0.15 <= distance_overtaker <= 2.85) verbleibende Messungen (N): {total_n}")
print(exclusion_info)
# --- Anzeige der reduzierten Statistiken als Tabelle ---
# Zeige nur Count, Mean, Median, Mode an
stats_reduced = stats_df.loc[["Count", "Mean", "Median", "Mode"]]
fig_stats, ax_stats = plt.subplots(figsize=(6, 2))
ax_stats.axis("tight")
ax_stats.axis("off")
table = ax_stats.table(cellText=stats_reduced.values,
rowLabels=stats_reduced.index,
colLabels=stats_reduced.columns,
loc='center')
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1.2, 1.2)
plt.title("Deskriptive Statistiken", fontsize=14)
plt.tight_layout()
plt.show()
# Prozentanteil der Überholvorgänge mit distance_overtaker < 1.51
below_1_51 = distances[distances < 1.51].count()
pct_below_1_51 = round((below_1_51 / total_n) * 100, 2) if total_n > 0 else 0
# --- Intervall-Kategorien ---
intervals = [
(0.15, 0.25),
(0.26, 0.5),
(0.51, 0.75),
(0.76, 1.00),
(1.01, 1.25),
(1.26, 1.50),
(1.51, 1.75),
(1.76, 2.00),
(2.01, 2.25),
(2.26, 2.50)
]
labels = []
counts = []
colors = []
for (low, high) in intervals:
# Zähle Werte im Intervall (inklusive obere Grenze)
count_val = distances[(distances >= low) & (distances <= high)].count()
labels.append(f"{low:.2f}-{high:.2f}")
counts.append(count_val)
# Farb-Logik:
# - Rot, falls Intervall-Ende <= 1.0
# - Orange, falls Intervall-Ende <= 1.5
# - Grün, sonst
if high <= 1.0:
colors.append("#ff4d4d")
elif high <= 1.5:
colors.append("#ffb732")
else:
colors.append("#5cb85c")
# Zusätzliche Kategorie: Messungen > 2.50 (bis 2.85, da vorherige Filterung)
extra_count = distances[distances > 2.50].count()
labels.append("Größer als 2.50")
counts.append(extra_count)
colors.append("#5cb85c") # Wieder grün
percentages = [round((c / total_n) * 100, 2) if total_n > 0 else 0 for c in counts]
# Plot-Layout festlegen
plt.style.use('ggplot')
plt.rcParams.update({
"font.size": 12,
"axes.titlesize": 14,
"axes.labelsize": 12,
"xtick.labelsize": 10,
"ytick.labelsize": 10,
"figure.figsize": (8, 6),
"axes.facecolor": "white",
"grid.color": "lightgray",
"grid.linestyle": "-",
"grid.linewidth": 0.8
})
# Änderung: Anzahl der Überholungen in Klammern setzen
main_title = f"OpenBikeSensor-Messungen auf Berner Strassen ({total_n} Überholungen)"
# --- Absolutes Histogramm ---
fig, ax = plt.subplots()
bars = ax.bar(labels, counts, color=colors, edgecolor="white")
ax.set_title(main_title, fontsize=14, pad=20)
ax.set_xlabel("Überholabstand [m]")
ax.set_ylabel("Häufigkeit")
ax.grid(axis="y", linestyle="--", alpha=0.7)
# Drehung der x-Achsen-Beschriftung um 45 Grad
plt.setp(ax.get_xticklabels(), rotation=45)
for bar in bars:
height = bar.get_height()
if height > 0:
ax.text(bar.get_x() + bar.get_width()/2, height + 0.2,
f"{int(height)}", ha="center", va="bottom",
fontsize=10, color="black")
plt.tight_layout(rect=[0, 0, 1, 0.88])
fig.text(0.5, 0.93, exclusion_info, ha="center", fontsize=9)
plt.show()
# --- Prozentuales Histogramm ---
fig2, ax2 = plt.subplots()
bars_pct = ax2.bar(labels, percentages, color=colors, edgecolor="white")
ax2.set_title(main_title, fontsize=14, pad=20)
ax2.set_xlabel("Überholabstand [m]")
ax2.set_ylabel("Prozent (%)")
ax2.grid(axis="y", linestyle="--", alpha=0.7)
# Drehung der x-Achsen-Beschriftung um 45 Grad
plt.setp(ax2.get_xticklabels(), rotation=45)
for bar in bars_pct:
height = bar.get_height()
if height > 0:
ax2.text(bar.get_x() + bar.get_width()/2, height + 0.5,
f"{height:.1f}%", ha="center", va="bottom",
fontsize=10, color="black")
plt.tight_layout(rect=[0, 0, 1, 0.88])
fig2.text(0.5, 0.93, f"{exclusion_info}\n(<1.51 m: {pct_below_1_51:.2f}%)", ha="center", fontsize=9)
plt.show()
# --- Speicherung der Auswertungen in eine CSV-Datei ---
output_file = "ueberholungen_alle_auswertung.csv"
with open(output_file, "w", encoding="utf-8", newline="") as f:
f.write("Deskriptive Statistiken\n")
stats_df.to_csv(f, index=True)
f.write(f"\nUrsprüngliche Gesamtanzahl (N):,{original_count}\n")
f.write(f"Messungen <0.15 ausgeschlossen:,{excluded_lower}\n")
f.write(f"Messungen >2.85 ausgeschlossen:,{excluded_upper}\n")
f.write(f"Nach Ausschluss (N):,{total_n}\n")
f.write(f"<1.51 Prozent:,{pct_below_1_51:.2f}%\n")
f.write(f"{exclusion_info}\n")
f.write("\nHistogramm (Absolut)\n")
f.write("Intervall,Count\n")
for label, val in zip(labels, counts):
f.write(f"{label},{val}\n")
f.write("\nHistogramm (Prozent)\n")
f.write("Intervall,Percentage\n")
for label, val in zip(labels, percentages):
f.write(f"{label},{val}\n")
print(f"\nAuswertungen wurden in '{output_file}' gespeichert.")
if __name__ == "__main__":
main()
Das Sprachmodell fügt jeweils auch Erklärungen zum Code ein. So kannst du diesen allenfalls anpassen.
Dieser Code macht dies:
Es wird eine Datei mit den Überholvorgängen eingelesen. In meinem Fall heisst sie „ueberholungen_alle_auswertung.json“. Diese Daten, die in diesem json sind, habe ich aus dem Portal über die Exportfunktion bekommen. Du wählt beim Export den gewünschten geografischen Bereich.
Dann werden Werte ausgeschlossen und statistische Bewertungen gemacht. Du bekommst Diagramme und ein CSV.
Oder wenn du nur bestimmte Strassen auswerten willst, dann kannst du dies ebenfalls mit den exportierten Daten aus dem Portal tun. Du musst dann Strassenstatistiken als GEO-json exportieren.
Beispielcode:
import os
import json
import csv
import statistics
import matplotlib.pyplot as plt
# --- Dateinamen festlegen und Pfade relativ zum Skript setzen ---
script_dir = os.path.dirname(os.path.abspath(__file__))
input_file = os.path.join(script_dir, 'bremgartenstrasse_segments.json')
output_file_v1 = os.path.join(script_dir, 'bremgartenstrasse_filtered_by_wayid_segments.csv')
output_file_v2 = os.path.join(script_dir, 'bremgartenstrasse_filtered_by_wayid_segments_filtered.csv')
freq_output_file = os.path.join(script_dir, 'bremgartenstrasse_frequency_distribution.csv')
diagram_file = os.path.join(script_dir, 'bremgartenstrasse_frequency_distribution.png')
hist_all_file = os.path.join(script_dir, 'bremgartenstrasse_hist_all_measurements.png')
# --- Gültige way_id-Werte (inklusive 57836821) ---
valid_way_ids = {558460732, 517178886, 654059256, 446160235, 57836821}
# --- Mapping der direction zu Label ---
direction_mapping = {1: "Nordosten", -1: "Südwesten"}
# --- JSON einlesen ---
try:
with open(input_file, 'r', encoding='utf-8') as file:
data = json.load(file)
except FileNotFoundError:
print(f"Die Datei '{input_file}' wurde nicht gefunden.")
exit(1)
except json.JSONDecodeError as error:
print("Fehler beim Dekodieren der JSON-Datei:", error)
exit(1)
# Falls die JSON-Daten in einem GeoJSON-ähnlichen Format (z. B. mit "features") vorliegen, extrahiere die Liste.
if isinstance(data, dict) and "features" in data:
data = data["features"]
# --- Filter: Nur Features mit gültiger way_id ---
filtered_features = [
feature for feature in data
if feature.get("properties", {}).get("way_id") in valid_way_ids
]
if not filtered_features:
print("Keine Einträge mit den angegebenen way_id-Werten gefunden.")
exit(0)
##########################################################################
# 1. Flache Aufbereitung: Alle Datensätze (für beide Versionen identisch) #
##########################################################################
def flatten_features(features):
"""
Wandelt eine Liste von Features in eine Liste flacher Dictionaries um.
Dabei wird der Array 'distance_overtaker_array' in einzelne Spalten
(z. B. distance_overtaker_array_0, distance_overtaker_array_1, …) aufgeteilt.
Liefert zudem die maximale Anzahl von Array-Spalten.
"""
flattened = []
max_array_len = 0
for feature in features:
props = feature.get("properties", {})
array_vals = props.get("distance_overtaker_array", [])
if isinstance(array_vals, list) and len(array_vals) > max_array_len:
max_array_len = len(array_vals)
record = props.copy()
record.pop("distance_overtaker_array", None)
if isinstance(array_vals, list):
for i, value in enumerate(array_vals):
record[f"distance_overtaker_array_{i}"] = value
flattened.append(record)
return flattened, max_array_len
flattened_data, max_array_length = flatten_features(filtered_features)
# Ergänze in den flach aufbereiteten Daten das Feld "richtung" basierend auf "direction"
for record in flattened_data:
if "direction" in record:
record["richtung"] = direction_mapping.get(record["direction"], "")
# Erstelle die Spaltennamen aus den flach aufbereiteten Daten.
all_keys = set()
for record in flattened_data:
all_keys.update(record.keys())
regular_keys = sorted([k for k in all_keys if not k.startswith("distance_overtaker_array_")])
array_keys = [f"distance_overtaker_array_{i}" for i in range(max_array_length)]
fieldnames_v1 = regular_keys + array_keys
if "richtung" not in fieldnames_v1:
fieldnames_v1.append("richtung")
# Für Version 2: Extra-Felder für Aggregation (Ausschlüsse und Häufigkeiten)
extra_fields = [
"excluded_count_lt_0.15", # Werte < 0.15 werden ausgeschlossen
"excluded_count_gt_2.85", # Werte > 2.85 werden ausgeschlossen
"freq_0.15_0.25",
"freq_0.26_0.50",
"freq_0.51_0.75",
"freq_0.76_1_00",
"freq_1.01_1_25",
"freq_1.26_1_50",
"freq_1.51_1_75",
"freq_1.76_2_00",
"freq_2.01_2_25",
"freq_2.26_2_50",
"freq_gt_2.50"
]
# Vermeide doppelte Feldnamen, falls flattened_data bereits einen der extra_keys enthält.
fieldnames_v2 = list(dict.fromkeys(fieldnames_v1 + extra_fields))
##########################################################################
# 2. Aggregation Version 1: Alle Events (ohne Filterung) #
##########################################################################
agg_values_v1 = {} # key: direction, value: Liste aller distance_overtaker_array-Werte
for feature in filtered_features:
props = feature.get("properties", {})
direction = props.get("direction")
arr = props.get("distance_overtaker_array", [])
if isinstance(arr, list):
agg_values_v1.setdefault(direction, []).extend(arr)
aggregated_rows_v1 = []
for direction in [-1, 1]:
values = agg_values_v1.get(direction, [])
if values:
computed_max = max(values)
computed_mean = statistics.mean(values)
computed_median = statistics.median(values)
event_count = len(values)
events_below_150 = sum(1 for v in values if v < 150)
else:
computed_max = ""
computed_mean = ""
computed_median = ""
event_count = 0
events_below_150 = 0
agg_row = {fn: "" for fn in fieldnames_v1}
agg_row["direction"] = direction
agg_row["distance_overtaker_max"] = computed_max
agg_row["distance_overtaker_mean"] = computed_mean
agg_row["distance_overtaker_median"] = computed_median
agg_row["overtaking_event_count"] = event_count
agg_row["overtaking_events_below_150"] = events_below_150
agg_row["name"] = "aggregiert"
agg_row["richtung"] = direction_mapping.get(direction, "")
aggregated_rows_v1.append(agg_row)
##########################################################################
# 3. Aggregation Version 2: Nur gültige Events (zwischen 0.15 und 2.85) #
# Zusätzlich: Zähle Ausschlüsse und führe Häufigkeitsauszählung durch #
##########################################################################
agg_stats_v2 = {}
for d in [-1, 1]:
agg_stats_v2[d] = {"values": [], "excluded_lt": 0, "excluded_gt": 0}
for feature in filtered_features:
props = feature.get("properties", {})
direction = props.get("direction")
arr = props.get("distance_overtaker_array", [])
if isinstance(arr, list):
for value in arr:
if value < 0.15:
agg_stats_v2[direction]["excluded_lt"] += 1
elif value > 2.85:
agg_stats_v2[direction]["excluded_gt"] += 1
else:
agg_stats_v2[direction]["values"].append(value)
aggregated_rows_v2 = []
def count_in_interval(values, lower, upper):
return sum(1 for v in values if lower <= v <= upper)
for direction in [-1, 1]:
stats = agg_stats_v2.get(direction, {"values": [], "excluded_lt": 0, "excluded_gt": 0})
valid_values = stats["values"]
if valid_values:
computed_max = max(valid_values)
computed_mean = statistics.mean(valid_values)
computed_median = statistics.median(valid_values)
event_count = len(valid_values)
events_below_150 = sum(1 for v in valid_values if v < 150)
else:
computed_max = ""
computed_mean = ""
computed_median = ""
event_count = 0
events_below_150 = 0
# Häufigkeitsauszählung in definierten Intervallen:
freq_0_15_0_25 = count_in_interval(valid_values, 0.15, 0.25)
freq_0_26_0_50 = count_in_interval(valid_values, 0.26, 0.50)
freq_0_51_0_75 = count_in_interval(valid_values, 0.51, 0.75)
freq_0_76_1_00 = count_in_interval(valid_values, 0.76, 1.00)
freq_1_01_1_25 = count_in_interval(valid_values, 1.01, 1.25)
freq_1_26_1_50 = count_in_interval(valid_values, 1.26, 1.50)
freq_1_51_1_75 = count_in_interval(valid_values, 1.51, 1.75)
freq_1_76_2_00 = count_in_interval(valid_values, 1.76, 2.00)
freq_2_01_2_25 = count_in_interval(valid_values, 2.01, 2.25)
freq_2_26_2_50 = count_in_interval(valid_values, 2.26, 2.50)
freq_gt_2_50 = sum(1 for v in valid_values if 2.50 < v <= 2.85)
agg_row = {fn: "" for fn in fieldnames_v2}
agg_row["direction"] = direction
agg_row["distance_overtaker_max"] = computed_max
agg_row["distance_overtaker_mean"] = computed_mean
agg_row["distance_overtaker_median"] = computed_median
agg_row["overtaking_event_count"] = event_count
agg_row["overtaking_events_below_150"] = events_below_150
agg_row["name"] = "aggregiert (gefiltert)"
agg_row["excluded_count_lt_0.15"] = stats["excluded_lt"]
agg_row["excluded_count_gt_2.85"] = stats["excluded_gt"]
agg_row["freq_0.15_0.25"] = freq_0_15_0_25
agg_row["freq_0.26_0.50"] = freq_0_26_0_50
agg_row["freq_0.51_0.75"] = freq_0_51_0_75
agg_row["freq_0.76_1_00"] = freq_0_76_1_00
agg_row["freq_1.01_1_25"] = freq_1_01_1_25
agg_row["freq_1.26_1_50"] = freq_1_26_1_50
agg_row["freq_1.51_1_75"] = freq_1_51_1_75
agg_row["freq_1.76_2_00"] = freq_1_76_2_00
agg_row["freq_2.01_2_25"] = freq_2_01_2_25
agg_row["freq_2.26_2_50"] = freq_2_26_2_50
agg_row["freq_gt_2.50"] = freq_gt_2_50
agg_row["richtung"] = direction_mapping.get(direction, "")
aggregated_rows_v2.append(agg_row)
##########################################################################
# 4. CSV-Dateien schreiben #
##########################################################################
# Version 1: Flache Daten + Aggregation (ohne Filterung)
try:
with open(output_file_v1, 'w', encoding='utf-8', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames_v1)
writer.writeheader()
for row in flattened_data:
writer.writerow(row)
for row in aggregated_rows_v1:
writer.writerow(row)
print(f"Version 1 (alle Events) wurde in '{output_file_v1}' geschrieben.")
except Exception as e:
print("Fehler beim Schreiben von Version 1:", e)
exit(1)
# Version 2: Flache Daten + Aggregation (mit Filterung, Ausschlusszählung und Häufigkeitsauszählung)
try:
with open(output_file_v2, 'w', encoding='utf-8', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames_v2)
writer.writeheader()
for row in flattened_data:
writer.writerow(row)
for row in aggregated_rows_v2:
writer.writerow(row)
print(f"Version 2 (gefiltert mit Ausschluss- und Häufigkeitsauszählung) wurde in '{output_file_v2}' geschrieben.")
except Exception as e:
print("Fehler beim Schreiben von Version 2:", e)
##########################################################################
# 5. Speichern der Häufigkeitsauszählung in einer eigenen CSV-Datei #
##########################################################################
freq_fieldnames = [
"direction",
"richtung",
"freq_0.15_0.25",
"freq_0.26_0.50",
"freq_0.51_0_75",
"freq_0.76_1_00",
"freq_1.01_1_25",
"freq_1.26_1_50",
"freq_1.51_1_75",
"freq_1.76_2_00",
"freq_2.01_2_25",
"freq_2.26_2_50",
"freq_gt_2.50",
"excluded_count_lt_0.15",
"excluded_count_gt_2.85"
]
try:
with open(freq_output_file, 'w', encoding='utf-8', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=freq_fieldnames)
writer.writeheader()
for row in aggregated_rows_v2:
freq_row = {key: row.get(key, "") for key in freq_fieldnames}
writer.writerow(freq_row)
print(f"Die Häufigkeitsauszählung wurde in '{freq_output_file}' geschrieben.")
except Exception as e:
print("Fehler beim Schreiben der Häufigkeitsauszählung:", e)
##########################################################################
# 6. Diagramm erstellen: Häufigkeitsauszählung visualisieren #
##########################################################################
plt.style.use('ggplot')
# Hilfsfunktion, um einen Wert sicher in int umzuwandeln
def safe_int(value):
try:
return int(value)
except (ValueError, TypeError):
return 0
# Definiere die Intervalle und entsprechende Farben.
interval_labels = [
"0.15-0.25", "0.26-0.50", "0.51-0.75", "0.76-1.00",
"1.01-1.25", "1.26-1.50", "1.51-1.75", "1.76-2.00",
"2.01-2.25", "2.26-2.50", "Größer als 2.50"
]
# Für eine Palette mit 11 Balken:
bar_colors = [
"#FF0000", "#FF3333", "#FF6666", "#FF9999", "#FFCCCC",
"#FFE5E5", "#CCFFCC", "#99FF99", "#66FF66", "#33FF33", "#00FF00"
]
fig, axs = plt.subplots(1, 2, figsize=(14, 6))
for idx, direction in enumerate([-1, 1]):
row = next((r for r in aggregated_rows_v2 if r.get("direction") == direction), None)
if row:
freq_counts = [
safe_int(row.get("freq_0.15_0.25", 0)),
safe_int(row.get("freq_0.26_0.50", 0)),
safe_int(row.get("freq_0.51_0.75", 0)),
safe_int(row.get("freq_0.76_1_00", 0)),
safe_int(row.get("freq_1.01_1_25", 0)),
safe_int(row.get("freq_1.26_1_50", 0)),
safe_int(row.get("freq_1.51_1_75", 0)),
safe_int(row.get("freq_1.76_2_00", 0)),
safe_int(row.get("freq_2.01_2_25", 0)),
safe_int(row.get("freq_2.26_2_50", 0)),
safe_int(row.get("freq_gt_2.50", 0))
]
total_n = sum(freq_counts)
label = direction_mapping.get(direction, f"Richtung {direction}")
# Balken zeichnen
bars = axs[idx].bar(interval_labels, freq_counts, edgecolor='black', linewidth=1.2, color=bar_colors)
axs[idx].set_title(f"Häufigkeitsverteilung ({label}), n = {total_n}", fontsize=14, pad=15)
axs[idx].set_xlabel("Intervall", fontsize=12, labelpad=10)
axs[idx].set_ylabel("Anzahl", fontsize=12, labelpad=10)
axs[idx].set_ylim(0, max(freq_counts) + 5)
axs[idx].grid(True, linestyle='--', alpha=0.7)
# Drehung der x-Achsen-Beschriftung um 45°:
axs[idx].tick_params(axis='x', labelrotation=45)
# Ausschlüsse pro Richtung anzeigen
excluded_text = f"Ausschlüsse: <0.15: {row['excluded_count_lt_0.15']}, >2.85: {row['excluded_count_gt_2.85']}"
axs[idx].text(0.02, 0.95, excluded_text, transform=axs[idx].transAxes,
fontsize=10, verticalalignment='top')
# Werte oberhalb der Balken platzieren
for bar in bars:
height = bar.get_height()
offset = height * 0.05 if height > 0 else 0.5
axs[idx].text(bar.get_x() + bar.get_width() / 2, height + offset,
f'{int(height)}', ha='center', va='bottom', fontsize=10)
else:
axs[idx].text(0.5, 0.5, "Keine Daten", transform=axs[idx].transAxes,
ha='center', va='center', fontsize=12)
fig.tight_layout()
plt.savefig(diagram_file, dpi=300)
plt.show()
print(f"Das Diagramm wurde als '{diagram_file}' gespeichert.")
##########################################################################
# 7. Histogramm aller Messungen (beide Richtungen) mit gleichen Intervallen #
##########################################################################
# Alle Messwerte aus den Features sammeln:
all_measurements = []
for feature in filtered_features:
props = feature.get("properties", {})
values = props.get("distance_overtaker_array", [])
if isinstance(values, list):
all_measurements.extend(values)
# Berechne die Frequenzen für die Intervalle:
freq_all = []
freq_all.append(sum(1 for v in all_measurements if 0.15 <= v <= 0.25))
freq_all.append(sum(1 for v in all_measurements if 0.26 <= v <= 0.50))
freq_all.append(sum(1 for v in all_measurements if 0.51 <= v <= 0.75))
freq_all.append(sum(1 for v in all_measurements if 0.76 <= v <= 1.00))
freq_all.append(sum(1 for v in all_measurements if 1.01 <= v <= 1.25))
freq_all.append(sum(1 for v in all_measurements if 1.26 <= v <= 1.50))
freq_all.append(sum(1 for v in all_measurements if 1.51 <= v <= 1.75))
freq_all.append(sum(1 for v in all_measurements if 1.76 <= v <= 2.00))
freq_all.append(sum(1 for v in all_measurements if 2.01 <= v <= 2.25))
freq_all.append(sum(1 for v in all_measurements if 2.26 <= v <= 2.50))
freq_all.append(sum(1 for v in all_measurements if 2.50 < v <= 2.85))
total_all = sum(freq_all)
fig_all, ax_all = plt.subplots(figsize=(10, 6))
bars_all = ax_all.bar(interval_labels, freq_all, edgecolor='black', linewidth=1.2, color=bar_colors)
ax_all.set_title(f"Histogramm aller Messungen, n = {total_all}", fontsize=14, pad=15)
ax_all.set_xlabel("Intervall", fontsize=12, labelpad=10)
ax_all.set_ylabel("Anzahl", fontsize=12, labelpad=10)
ax_all.set_ylim(0, max(freq_all) + 5)
ax_all.grid(True, linestyle='--', alpha=0.7)
# Drehung der x-Achsen-Beschriftungen um 45°:
ax_all.tick_params(axis='x', labelrotation=45)
# Berechne die Gesamtausschlüsse über alle Messungen:
excluded_all_lt = sum(1 for v in all_measurements if v < 0.15)
excluded_all_gt = sum(1 for v in all_measurements if v > 2.85)
excluded_all_text = f"Ausschlüsse: <0.15: {excluded_all_lt}, >2.85: {excluded_all_gt}"
ax_all.text(0.02, 0.95, excluded_all_text, transform=ax_all.transAxes,
fontsize=10, verticalalignment='top')
# Werte oberhalb der Balken platzieren
for bar in bars_all:
height = bar.get_height()
offset = height * 0.05 if height > 0 else 0.5
ax_all.text(bar.get_x() + bar.get_width()/2, height + offset,
f'{int(height)}', ha='center', va='bottom', fontsize=10)
fig_all.tight_layout()
plt.savefig(hist_all_file, dpi=300)
plt.show()
print(f"Das Histogramm aller Messungen wurde als '{hist_all_file}' gespeichert.")
Du musst die die Wayids der OSM-Segmente angeben, welche die jeweilige Strasse hat. Und im Code ist ebenfalls die Richtung drin. # — Mapping der direction zu Label —
direction_mapping = {1: „Nordosten“, -1: „Südwesten“} in meinem Beispiel.