wenn ich es richtig interpretiere, werden derzeit alle hochgeladenen Tracks für die Straßenkategorisierung verwendet und nicht lediglich die vom User als Public markierten Tracks?
Wenn die Tracks per Sensorbox direkt hochgeladen werden, habe ich zunächst keinen Einfluss auf die Dateien/Tracks die hochgeladen werden. Naturgemäß ist darunter natürlich auch der ein oder andere Unsinn dabei.
Beispiel:
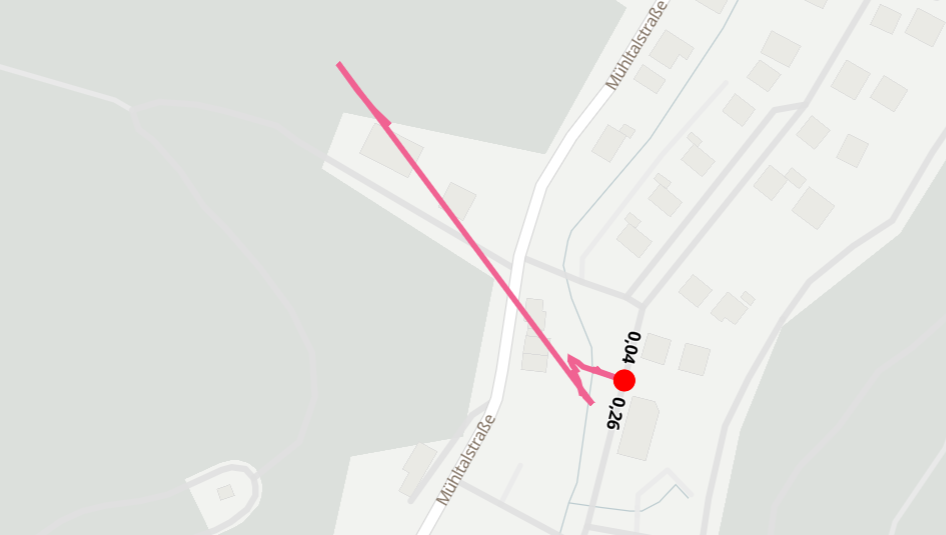
Das Rad stand vor der Garage, hatte GPS empfang und es wurde ein rechter und linker Sensortest gelogged - fertig.
Das führt zu folgender Kategorisierung:
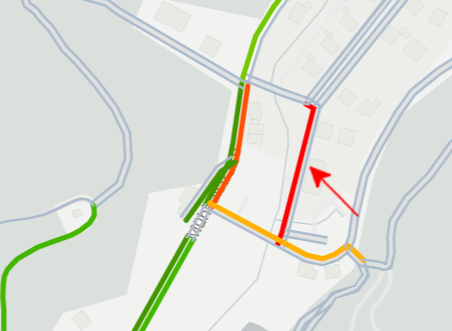
Der Veröffentlichungsstatus des für diese Kategorisierung verwendeten Tracks ist Private.
Würde es nicht Sinn machen die für die Kategorisierung verwendeten Tracks näher zu kennzeichnen?
-
manuelle Freigabe. Der Track wird vom Benutzer manuell für die Verwendung in der Kategorisierung freigegeben (zusätzlicher Haken)
-
automatisch: Verwerfen von Tracks mit einer Gesamtlänge von weniger als x Metern
-
automatisch: Verwerfen von Tracks mit weniger als x Überholvorgängen
Ring frei für den Diskurs in Discourse!
Beste Grüße
Peter
 Solche Plausibilitätschecks und künftig eben auch manuelle Qualitätssicherung sollten uns langfristig helfen, die Datenqualität sehr zu erhöhen. Bis dahin sollte es m.E. die Aufgabe jeder:s Nutzer:in sein, die eigenen Daten auf Korrektheit zu prüfen, und Blödsinns-Tracks wieder zu löschen.
Solche Plausibilitätschecks und künftig eben auch manuelle Qualitätssicherung sollten uns langfristig helfen, die Datenqualität sehr zu erhöhen. Bis dahin sollte es m.E. die Aufgabe jeder:s Nutzer:in sein, die eigenen Daten auf Korrektheit zu prüfen, und Blödsinns-Tracks wieder zu löschen.